在學程式設計一段時間,漸漸會碰到一個技術 - 網路爬蟲 ,爬蟲是個既好學又難學的東西,只要你搞懂了網頁的架構邏輯,那要爬任何網站還不是分分鐘的事情?今天我們先從簡單的爬蟲開始教學。
緣由
作者除了是資工系學生以外,平時也常常在網路上接案貼補家用。但小弟我生性害羞,個人不太敢去網路上求案,所以通常都是在 Facebook社團 及 ptt code_job版上找case來做。雖然現在不少人會在 Tasker之類的網站接案,但那多都需要付費成為會員才能接案,所以並不在我們窮學生的選項內。
而時間就是金錢,常常有人在板上發一些我有興趣或我有能力吃下的案子,但因為我總是太慢才看到,所以往往多變成「洽談中」或「已發案」的狀態了。所以前陣子就寫了一個小程式,每過一段時間就檢查有沒有符合我篩選後關鍵字的案子,有的話 Line Bot 就會自動傳訊息給我,從此之後,我就過著數錢數到手軟的生活 ( 但很可惜並沒有發生 )。
走訪探查
要逛ptt 基本上就是開cmd走 telnet,但小弟不才,所以那部分就沒有涉獵了,不知道要怎麼從telnet的渠道去爬蟲,好在 ptt 有網頁版,完美解決我們的問題。
Code_job 版網址是 https://www.ptt.cc/bbs/CodeJob/index.html ,看起來挺容易爬的,雖然有分頁,但 index 預設就是最新的。
尋找方法
那讓我們思考一下,我如何才能取得最新的文章呢?把公告濾掉,然後直接抓最後一篇或許是個直覺的方法,但考量到可能新發案會突然短時間發出兩、三篇,所以這個方式並不是個完美的方法。
接著又想,若我能去記錄上一次爬蟲拿到的最後一篇文章,就能知道這次爬蟲新抓取的篇數。這樣確實可行,但不直觀,至少我要有個地方去記錄上次文章,要嘛就是 database,要嘛就是存 file,兩種都還要額外的地方去處理。
然後再想,若上面有時間的話,那我可以去比對時間,例如爬蟲五分鐘爬一次,那我就能去算五分鐘內生成的文章有多少。但事情看起來沒那麼簡單,畫面上只有日期,日期範圍又太大了。
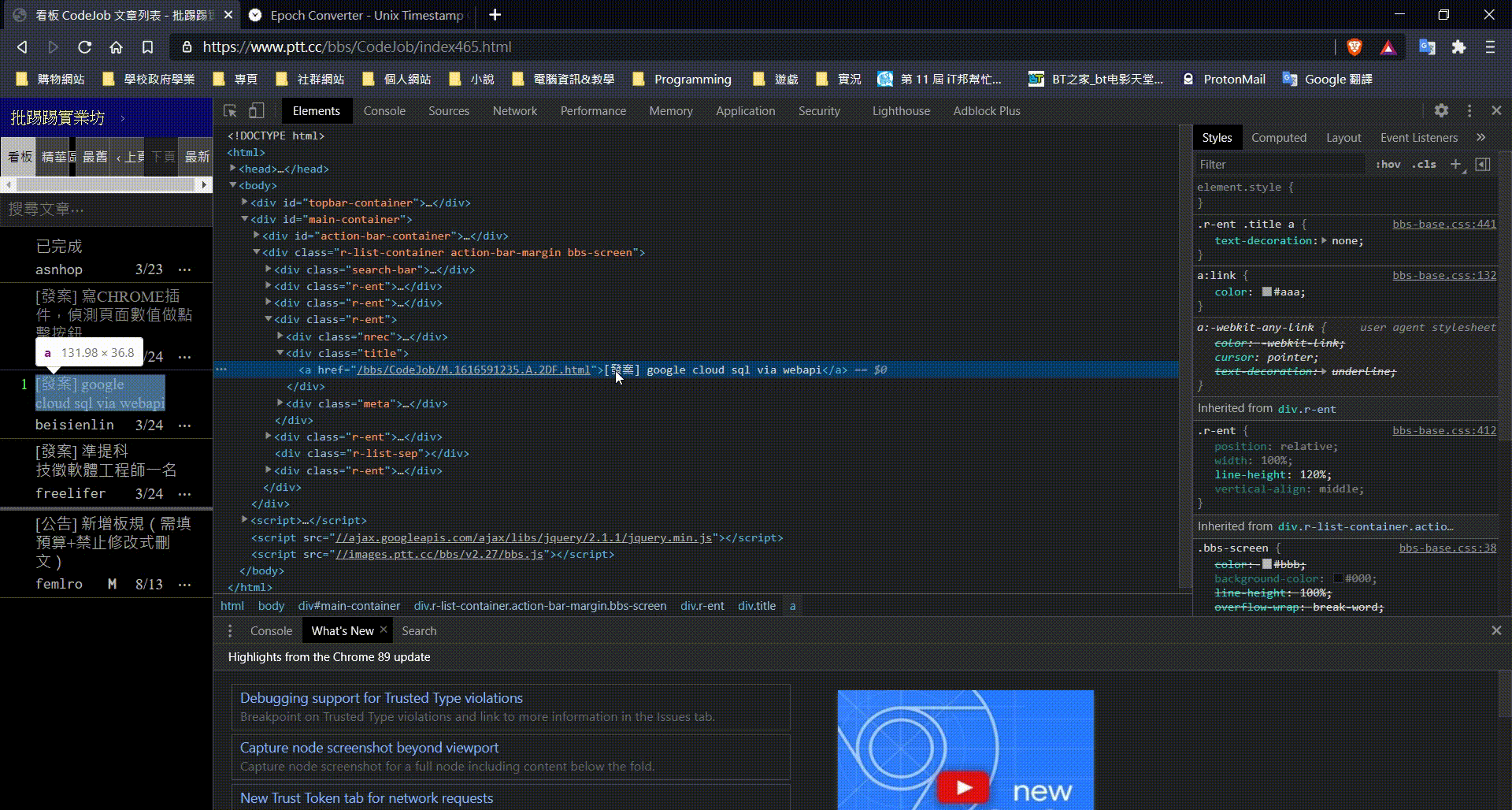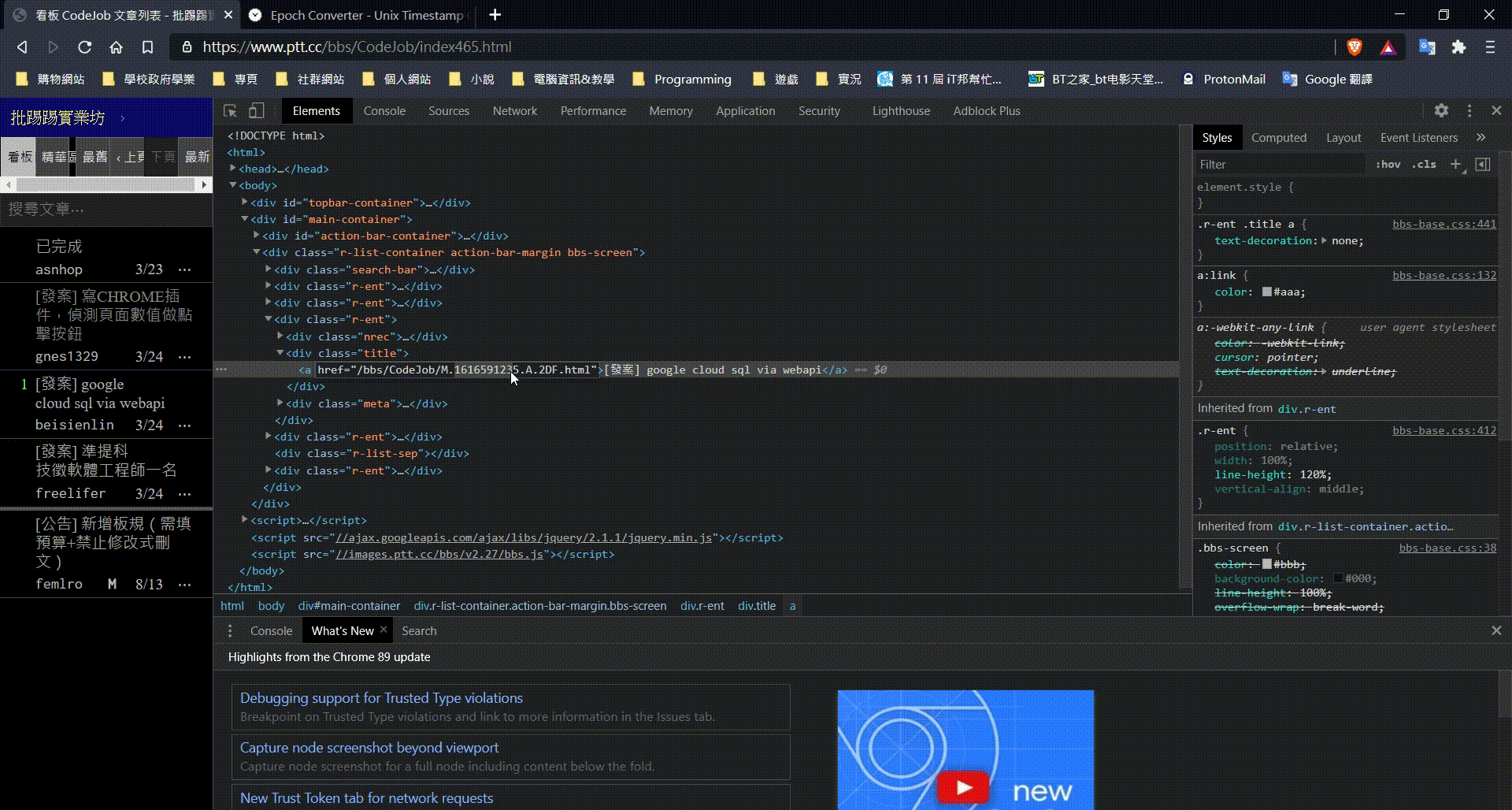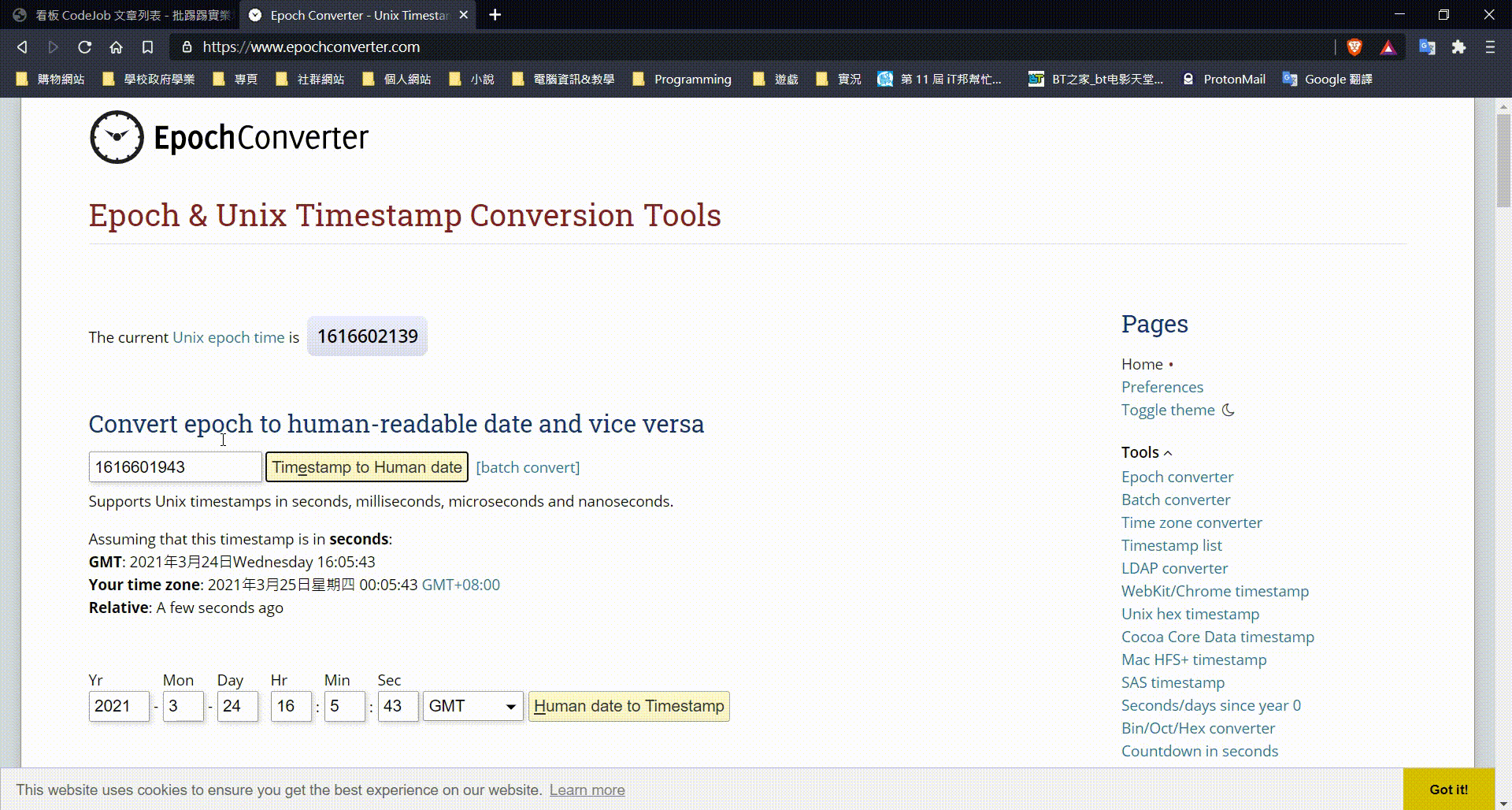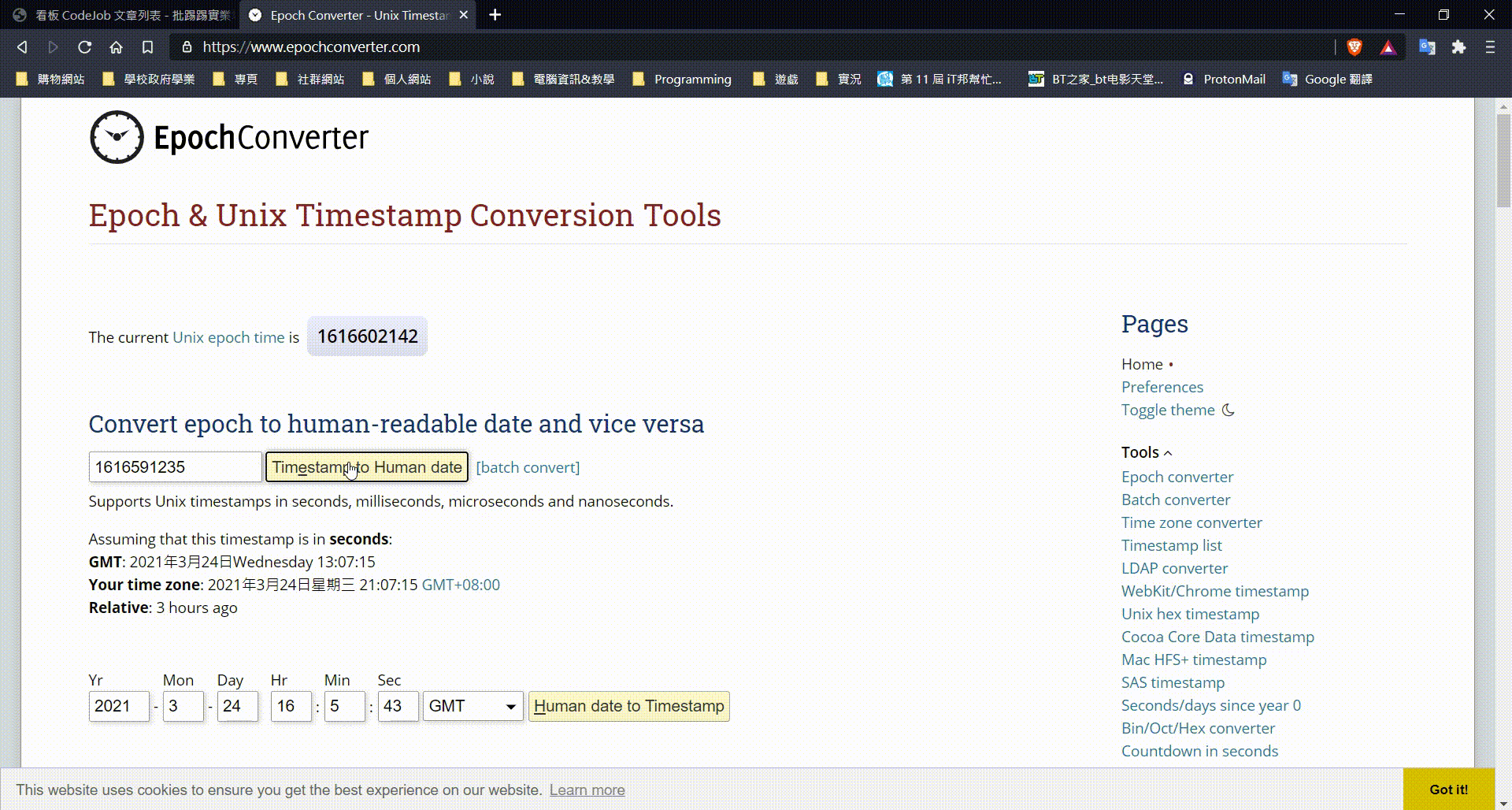
觀察物件
持續觀察上面有的物件,突然瞄到一個有趣的東西,文章的連結。這個連結中,有一個 10 位數又 16 開頭的數字,憑著上學期國川教的東西,這肯定就是 timestamp。
分解研究
我們把動作分解成幾個:
- 抓取網頁
- 將文章列表抓出
- filter 5 分鐘內的文章

想看看我 Javascript執行效果的人,可以參考下面這段程式碼。
1 | $('.r-ent a').map((index, obj)=>{ |
因為單純是 get request,我想應該也沒有研究的必要了XDDD,就直接來研究抓取 dom 就可以了。確認可以抓到文章列表,那剩下的就是 filter 的事情了。
實作程式碼
Define 抓取時間
先定義 一個 crontab 會抓取的時間數值
1 | const CrontabPeriod = 60 * 60 * 24 * 1 // 先預設1天做測試,完成後再改回五分鐘 |
取得文章列表
然後直接用 request 來抓取 code_job 版,然後再把文章 list 抓出來
1 | request('https://www.ptt.cc/bbs/CodeJob/index.html', (err, res, body) => { |
filter
最後加入 timestamp 的 filter
1 | // filter 時間 |
完整程式碼
1 | const request = require('request'); |
衍伸應用
我們可以透過 crontab 來設定每五分鐘 trigger 一次,同時加上 heroku webhook 來達到自動通知,bot的部分我們可以選用 Line bot 或 Telegram bot會比較好上手。
其實爬蟲並不是要多厲害的技術,而真正有價值的是在於解決問題和省下時間。像是這次介紹的 ptt code_job 主動發文通知,就是一種很簡單,實作不困難,但卻能為我們省下許多的時間。
